VolCurve, VolSurface, ProbCurve, and ProbSurface in application code.
Pipeline
Library position
OIPD is closer to an end-to-end volatility and probability pipeline than to a box of separate numerical parts. Libraries such as QuantLib provide strong components for individual stages, including IV solvers and smile fitters. OIPD wires the data cleaning, volatility fitting, surface construction, probability conversion, and diagnostics into one public interface.SVI benchmark
To benchmark OIPD’s SVI fitter, we compare it against QuantLib’s SVI fitter (SviInterpolatedSmileSection). The test keeps OIPD’s preprocessing and data-cleaning pipeline fixed, and only swaps the SVI calibration step.
The fitted smiles below use the same AAPL dataset and expiry.
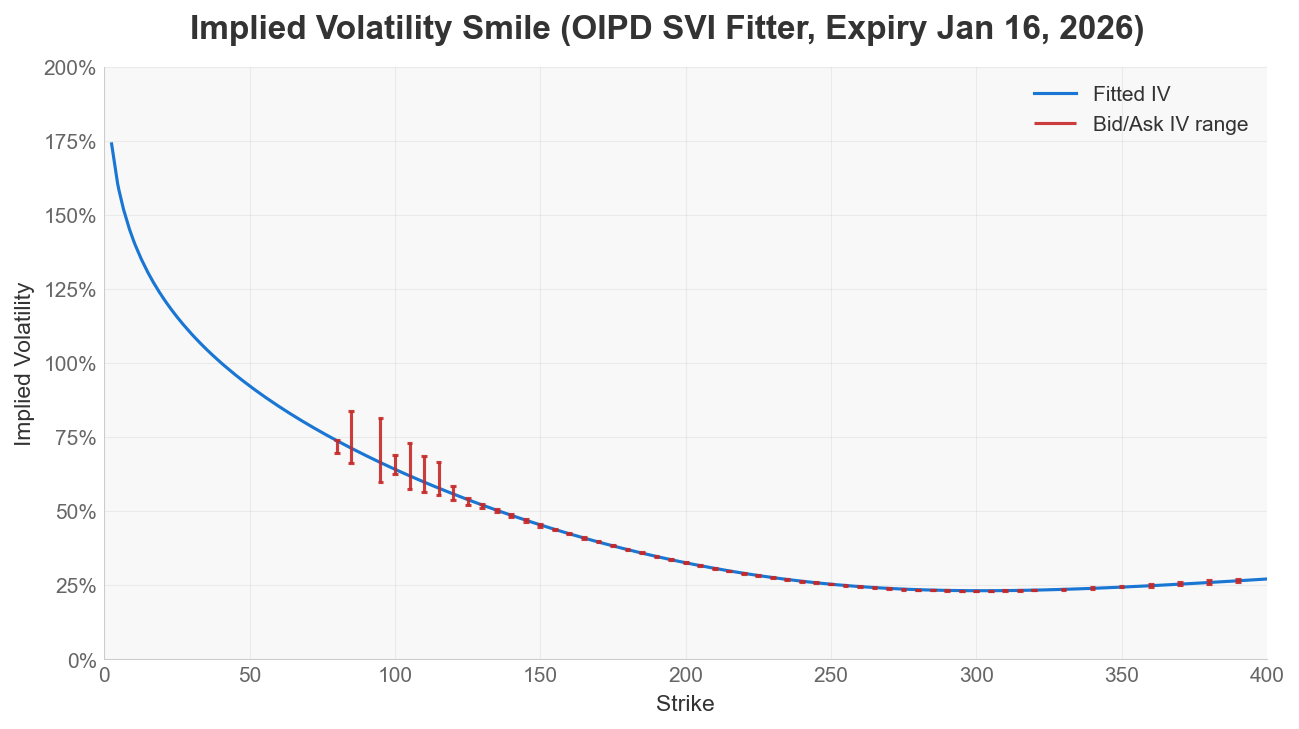
OIPD SVI fitter
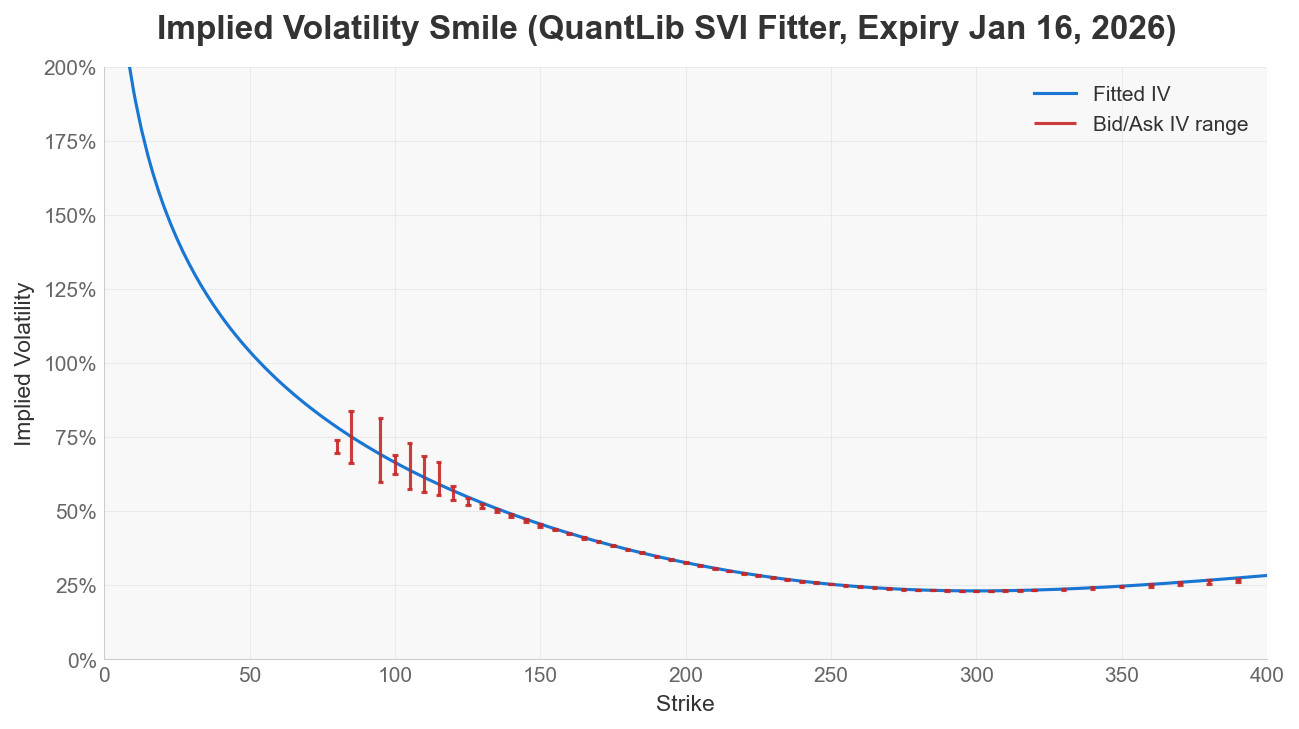
QuantLib SVI fitter (OIPD preprocessing + QuantLib calibration)
- full pipeline run time
- vega-weighted RMSE
- butterfly arbitrage checks, using 2 checks to detect arbitrage: (1) min(g(k)) and (2) negative density
QuantLib’s SVI fitter was significantly faster in this test, as it is written in C++. OIPD’s fit was cleaner on the tested arbitrage checks.
For arbitrage checks, higher
min(g(k)) is better, and any negative value is a warning for butterfly arbitrage. Likewise, lower values are better for both Share of grid with g(k) < 0 and Negative RND grid points; 0 is the clean no-violation outcome on the tested grid.
Treat this benchmark as one tested example, not a universal comparison between the libraries.